Introduce Auto-Boost-Essential
This commit is contained in:
817
Auto-Boost-Essential/Auto-Boost-Essential.py
Normal file
817
Auto-Boost-Essential/Auto-Boost-Essential.py
Normal file
@@ -0,0 +1,817 @@
|
|||||||
|
# /// script
|
||||||
|
# requires-python = ">=3.12"
|
||||||
|
# dependencies = [
|
||||||
|
# "vstools",
|
||||||
|
# ]
|
||||||
|
# ///
|
||||||
|
|
||||||
|
# Requires manually installing:
|
||||||
|
# SVT-AV1-Essential: https://github.com/nekotrix/SVT-AV1-Essential/releases
|
||||||
|
# Vship (GPU): https://github.com/Line-fr/Vship/releases
|
||||||
|
# or vs-zip (CPU): https://github.com/dnjulek/vapoursynth-zip/releases/tag/R6
|
||||||
|
# and FFMS2: https://github.com/FFMS/ffms2/releases
|
||||||
|
# in your system PATH or the script's directory
|
||||||
|
|
||||||
|
# Auto-Boost-Essential
|
||||||
|
# Copyright (c) Trix and contributors
|
||||||
|
# Thanks to the AV1 discord community members <3
|
||||||
|
#
|
||||||
|
#
|
||||||
|
# Permission is hereby granted, free of charge, to any person obtaining
|
||||||
|
# a copy of this software and associated documentation files (the "Software"),
|
||||||
|
# to deal in the Software without restriction, including without limitation
|
||||||
|
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
|
||||||
|
# and/or sell copies of the Software, and to permit persons to whom the
|
||||||
|
# Software is furnished to do so, subject to the following conditions:
|
||||||
|
#
|
||||||
|
# The above copyright notice and this permission notice shall be
|
||||||
|
# included in all copies or substantial portions of the Software.
|
||||||
|
#
|
||||||
|
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||||
|
# EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
||||||
|
# MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
|
||||||
|
# IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
|
||||||
|
# DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
|
||||||
|
# ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
|
||||||
|
# DEALINGS IN THE SOFTWARE.
|
||||||
|
|
||||||
|
from vstools import vs, core, clip_async_render
|
||||||
|
from statistics import quantiles
|
||||||
|
from math import ceil
|
||||||
|
from pathlib import Path
|
||||||
|
import subprocess
|
||||||
|
import argparse
|
||||||
|
import shutil
|
||||||
|
import struct
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument("-s", "--stage", help = "Select stage: 1 = fast encode, 2 = calculate metrics, 3 = generate zones, 4 = final encode | Default: all", default=0)
|
||||||
|
parser.add_argument("-i", "--input", required=True, help = "Video input filepath (original source file)")
|
||||||
|
parser.add_argument("-t", "--temp", help = "The temporary directory for the script to store files in | Default: video input filename")
|
||||||
|
parser.add_argument("--fast-speed", help = "Fast encode speed (Allowed: medium, fast, faster) | Default: faster", default="faster")
|
||||||
|
parser.add_argument("--final-speed", help = "Final encode speed (Allowed: slower, slow, medium, fast, faster) | Default: slow", default="slow")
|
||||||
|
parser.add_argument("--quality", help = "Base encoder --quality (Allowed: low, medium, high) | Default: medium", default="medium")
|
||||||
|
parser.add_argument("-a", "--aggressive", action='store_true', help = "More aggressive boosting | Default: not active")
|
||||||
|
parser.add_argument("-u", "--unshackle", action='store_true', help = "Less restrictive boosting | Default: not active")
|
||||||
|
parser.add_argument("--fast-params", help="Custom fast encoding parameters")
|
||||||
|
parser.add_argument("--final-params", help="Custom final encoding parameters")
|
||||||
|
#parser.add_argument("-g", "--grain-format", help = "Select grain format: 1 = SVT-AV1 film-grain, 2 = Photon-noise table | Default: 1", default=1)
|
||||||
|
parser.add_argument("--cpu", action='store_true', help = "Force the usage of vs-zip (CPU) instead of Vship (GPU) | Default: not active")
|
||||||
|
parser.add_argument("--verbose", action='store_true', help = "Enable more verbosity | Default: not active")
|
||||||
|
parser.add_argument("-r", "--resume", action='store_true', help = "Resume an uncompleted encode | Default: not active")
|
||||||
|
parser.add_argument("-nb", "--no-boosting", action='store_true', help = "Runs the script without boosting (final encode only) | Default: not active")
|
||||||
|
parser.add_argument("-v", "--version", action='store_true', help = "Print script version")
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
stage = int(args.stage)
|
||||||
|
src_file = Path(args.input).resolve()
|
||||||
|
file_ext = src_file.suffix
|
||||||
|
output_dir = src_file.parent
|
||||||
|
tmp_dir = Path(args.temp).resolve() if args.temp is not None else output_dir / src_file.stem
|
||||||
|
vpy_file = tmp_dir / f"{src_file.stem}.vpy"
|
||||||
|
cache_file = tmp_dir / f"{src_file.stem}.ffindex"
|
||||||
|
fast_output_file = tmp_dir / f"{src_file.stem}_fastpass.ivf"
|
||||||
|
tmp_final_output_file = tmp_dir / f"{src_file.stem}.ivf"
|
||||||
|
final_output_file = output_dir / f"{src_file.stem}.ivf"
|
||||||
|
ssimu2_log_file = tmp_dir / f"{src_file.stem}_ssimu2.log"
|
||||||
|
zones_file = tmp_dir / f"{src_file.stem}_zones.cfg"
|
||||||
|
stage_file = tmp_dir / f"{src_file.stem}_stage.txt"
|
||||||
|
stage_resume = 0
|
||||||
|
fast_speed = args.fast_speed
|
||||||
|
final_speed = args.final_speed
|
||||||
|
quality = args.quality
|
||||||
|
aggressive = args.aggressive
|
||||||
|
unshackle = args.unshackle
|
||||||
|
fast_params = args.fast_params
|
||||||
|
final_params = args.final_params
|
||||||
|
#grain_format = args.grain_format # upcoming auto-FGS feature
|
||||||
|
cpu = args.cpu
|
||||||
|
verbose = args.verbose
|
||||||
|
resume = args.resume
|
||||||
|
no_boosting = args.no_boosting
|
||||||
|
version = args.version
|
||||||
|
|
||||||
|
if version:
|
||||||
|
print(f"Auto-Boost-Essential v1.0 (Release)")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if not os.path.exists(src_file):
|
||||||
|
print(f"The source input doesn't exist. Double-check the provided path.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if fast_speed not in ["medium", "fast", "faster"]:
|
||||||
|
print(f"The fast pass speed must be either medium, fast or faster.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if final_speed not in ["slower", "slow", "medium", "fast", "faster"]:
|
||||||
|
print(f"The final pass speed must be either slower, slow, medium, fast or faster.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if quality not in ["low", "medium", "high"]:
|
||||||
|
print(f"The quality preset must be either low, medium or high.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if stage != 0 and resume:
|
||||||
|
print(f"Resume will auto-resume from the last (un)completed stage. You cannot provide both stage and resume.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
if os.path.exists(tmp_dir):
|
||||||
|
if resume and os.path.exists(stage_file):
|
||||||
|
with open(stage_file, "r") as f:
|
||||||
|
lines = f.readlines()
|
||||||
|
stage_resume = int(lines[0].strip())
|
||||||
|
if stage_resume == 5:
|
||||||
|
print(f'Final encode already finished. Nothing to resume.')
|
||||||
|
exit(0)
|
||||||
|
else:
|
||||||
|
print(f'Resuming from stage {stage_resume}.')
|
||||||
|
|
||||||
|
if not resume and stage in [0, 1]:
|
||||||
|
shutil.rmtree(tmp_dir)
|
||||||
|
|
||||||
|
if not os.path.exists(tmp_dir):
|
||||||
|
os.makedirs(tmp_dir)
|
||||||
|
|
||||||
|
if not os.path.exists(vpy_file):
|
||||||
|
with open(vpy_file, 'w') as file:
|
||||||
|
file.write(
|
||||||
|
f"""
|
||||||
|
from vstools import core, depth, DitherType, set_output
|
||||||
|
core.max_cache_size = 1024
|
||||||
|
src = core.ffms2.Source(source=r"{src_file}", cachefile=r"{cache_file}")
|
||||||
|
src = depth(src, 10, dither_type=DitherType.NONE)
|
||||||
|
set_output(src)
|
||||||
|
"""
|
||||||
|
)
|
||||||
|
|
||||||
|
core.max_cache_size = 1024
|
||||||
|
|
||||||
|
def read_from_offset(file_path: Path, offset: int, size: int) -> bytes:
|
||||||
|
with open(file_path, 'rb') as file:
|
||||||
|
file.seek(offset)
|
||||||
|
data = file.read(size)
|
||||||
|
return data
|
||||||
|
|
||||||
|
def merge_ivf_parts(base_path: Path, output_path: Path, fwidth: int, fheight: int) -> None:
|
||||||
|
# Collect ivf parts
|
||||||
|
base = base_path.stem.split("__")[0]
|
||||||
|
parts = sorted(
|
||||||
|
base_path.parent.glob(f"{base}__*.ivf"),
|
||||||
|
key=lambda p: int(p.stem.split("__")[-1])
|
||||||
|
)
|
||||||
|
final_part = base_path.parent / f"{base}.ivf"
|
||||||
|
if final_part.exists():
|
||||||
|
parts.append(final_part)
|
||||||
|
|
||||||
|
if not parts:
|
||||||
|
print("No parts found to merge. Muxing aborted.")
|
||||||
|
return
|
||||||
|
|
||||||
|
num_frames = 0
|
||||||
|
framedata = b''
|
||||||
|
i = 0
|
||||||
|
for i in range(len(parts)):
|
||||||
|
|
||||||
|
if not os.path.exists(parts[i]):
|
||||||
|
print(f"Part {i} not found. Muxing aborted.")
|
||||||
|
return
|
||||||
|
|
||||||
|
num_frames += int.from_bytes(read_from_offset(parts[i], 24, 4), 'little')
|
||||||
|
framedata += read_from_offset(parts[i], 32, -1)
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
with open(output_path, "wb+") as f:
|
||||||
|
fps_num = 24000
|
||||||
|
fps_den = 1001
|
||||||
|
header = struct.pack(
|
||||||
|
'<4sHH4sHHIII4s',
|
||||||
|
b'DKIF', # Signature 0x00
|
||||||
|
0, # Version 0x04
|
||||||
|
32, # Header size (don't change this) 0x06
|
||||||
|
b'AV01', # Codec FourCC 0x08
|
||||||
|
fwidth, # Width 0x0C
|
||||||
|
fheight, # Height 0x0E
|
||||||
|
fps_num, # Framerate numerator 0x10
|
||||||
|
fps_den, # Framerate denominator 0x14
|
||||||
|
num_frames, # Number of frames (can be 0 initially) 0x18
|
||||||
|
b'\0\0\0\0' # Reserved 0x1C
|
||||||
|
# Follows array of frame headers
|
||||||
|
)
|
||||||
|
f.write(header)
|
||||||
|
f.write(framedata)
|
||||||
|
offset = 32 # Frame data start
|
||||||
|
for i in range(num_frames): # Rewrite timestamps
|
||||||
|
f.seek(offset) # Jump to header
|
||||||
|
size = int.from_bytes(f.read(4), 'little') # Get size of frame data
|
||||||
|
f.write(i.to_bytes(8, "little")) # Rewrite the timestamp
|
||||||
|
offset += 12 + size # Size of frame + size of frame header
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print(f"Merged {len(parts)} chunks into {output_path} ({num_frames} total frames)")
|
||||||
|
|
||||||
|
def create_offset_zones_file(original_zones_path: Path, offset_zones_path: Path, offset_frames: int) -> None:
|
||||||
|
"""
|
||||||
|
Creates a new zones file with frame ranges offset by the specified number of frames.
|
||||||
|
Removes zones that become invalid (end <= 0).
|
||||||
|
|
||||||
|
:param original_zones_path: path to original zones file
|
||||||
|
:type original_zones_path: Path
|
||||||
|
:param offset_zones_path: path to new offset zones file
|
||||||
|
:type offset_zones_path: Path
|
||||||
|
:param offset_frames: number of frames to subtract from zone ranges
|
||||||
|
:type offset_frames: int
|
||||||
|
"""
|
||||||
|
if no_boosting:
|
||||||
|
return
|
||||||
|
|
||||||
|
if not original_zones_path.exists():
|
||||||
|
print(f"Original zones file {original_zones_path} not found!")
|
||||||
|
return
|
||||||
|
|
||||||
|
with original_zones_path.open("r") as file:
|
||||||
|
zones_content = file.read().strip()
|
||||||
|
|
||||||
|
if not zones_content.startswith("Zones :"):
|
||||||
|
print(f"Invalid zones file format in {original_zones_path}")
|
||||||
|
return
|
||||||
|
|
||||||
|
zones_data = zones_content.replace("Zones :", "").strip()
|
||||||
|
zone_parts = [zone.strip() for zone in zones_data.split(";") if zone.strip()]
|
||||||
|
|
||||||
|
offset_zones = []
|
||||||
|
for zone in zone_parts:
|
||||||
|
parts = zone.split(",")
|
||||||
|
if len(parts) not in [3, 4]:
|
||||||
|
continue
|
||||||
|
|
||||||
|
start = int(parts[0])
|
||||||
|
end = int(parts[1])
|
||||||
|
crf = parts[2]
|
||||||
|
|
||||||
|
new_start = start - offset_frames
|
||||||
|
new_end = end - offset_frames
|
||||||
|
|
||||||
|
# Skip invalid zones
|
||||||
|
if new_end <= 0:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Clamp start to 0 if it goes negative (though this shouldn't happen with keyframe boundaries)
|
||||||
|
if new_start < 0:
|
||||||
|
new_start = 0
|
||||||
|
|
||||||
|
offset_zones.append(f"{new_start},{new_end},{crf}")
|
||||||
|
|
||||||
|
if offset_zones:
|
||||||
|
with offset_zones_path.open("w") as file:
|
||||||
|
file.write(f"Zones : {';'.join(offset_zones)};")
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print(f"Offset: {offset_frames} frames")
|
||||||
|
print(f"Zones: {len(zone_parts)} -> {len(offset_zones)}")
|
||||||
|
else:
|
||||||
|
print(f"No valid zones remaining after offset of {offset_frames} frames")
|
||||||
|
|
||||||
|
def read_ivf_frames(path: Path) -> tuple[bytes, list]:
|
||||||
|
frames = []
|
||||||
|
with open(path, "rb") as f:
|
||||||
|
header = f.read(32) # IVF header
|
||||||
|
while True:
|
||||||
|
frame_header = f.read(12)
|
||||||
|
if len(frame_header) < 12:
|
||||||
|
break
|
||||||
|
size, timestamp = struct.unpack("<IQ", frame_header)
|
||||||
|
frame_data = f.read(size)
|
||||||
|
if len(frame_data) < size:
|
||||||
|
break
|
||||||
|
frames.append((size, timestamp, frame_data))
|
||||||
|
return header, frames
|
||||||
|
|
||||||
|
def trim_ivf_from_last_keyframe(ivf_path: Path, ivf_out_path: Path, last_gop_start_index: int) -> None:
|
||||||
|
header, frames = read_ivf_frames(ivf_path)
|
||||||
|
trimmed_frames = frames[:last_gop_start_index]
|
||||||
|
if verbose:
|
||||||
|
print(f"Encode frame count: {len(frames)}")
|
||||||
|
print(f"Keeping {len(trimmed_frames)} frames (removing last GOP starting at frame {last_gop_start_index})")
|
||||||
|
|
||||||
|
with open(ivf_out_path, "wb") as f:
|
||||||
|
new_header = bytearray(header)
|
||||||
|
new_header[24:28] = struct.pack("<I", len(trimmed_frames))
|
||||||
|
f.write(new_header)
|
||||||
|
|
||||||
|
for size, timestamp, frame_data in trimmed_frames:
|
||||||
|
f.write(struct.pack("<IQ", size, timestamp))
|
||||||
|
f.write(frame_data)
|
||||||
|
|
||||||
|
def get_next_filename(base_path: Path) -> Path:
|
||||||
|
"""
|
||||||
|
Gets the next available ivf or zones filename for resumed encodes.
|
||||||
|
|
||||||
|
:param base_path: path to base file
|
||||||
|
:type base_path: Path
|
||||||
|
|
||||||
|
:return: path to next available file
|
||||||
|
:rtype: Path
|
||||||
|
"""
|
||||||
|
base = base_path.stem
|
||||||
|
suffix = base_path.suffix
|
||||||
|
parent = base_path.parent
|
||||||
|
|
||||||
|
files = sorted(parent.glob(f"{base}__*{suffix}"), key=lambda x: int(x.stem.split("__")[-1]))
|
||||||
|
if not files:
|
||||||
|
return parent / f"{base}__1{suffix}"
|
||||||
|
|
||||||
|
last_index = int(files[-1].stem.split("__")[-1])
|
||||||
|
return parent / f"{base}__{last_index + 1}{suffix}"
|
||||||
|
|
||||||
|
def get_total_previous_frames(enc_file: Path) -> int:
|
||||||
|
"""
|
||||||
|
Sum the frame counts of all previously trimmed encode files like encode__1.ivf + encode__2.ivf...
|
||||||
|
|
||||||
|
:param enc_file: path to encode
|
||||||
|
:type enc_file: Path
|
||||||
|
|
||||||
|
:return: frame number
|
||||||
|
:rtype: int
|
||||||
|
"""
|
||||||
|
base = enc_file.stem.split("__")[0]
|
||||||
|
ivf_files = sorted(enc_file.parent.glob(f"{base}__*.ivf"), key=lambda x: int(x.stem.split('__')[-1]))
|
||||||
|
|
||||||
|
total = 0
|
||||||
|
for f in ivf_files:
|
||||||
|
with open(f, "rb") as ivf:
|
||||||
|
ivf.seek(24)
|
||||||
|
frame_count = int.from_bytes(ivf.read(4), "little")
|
||||||
|
total += frame_count
|
||||||
|
return total
|
||||||
|
|
||||||
|
def get_file_info(file: Path, mode: str) -> tuple[list[int], bool, int, int, int]:
|
||||||
|
"""
|
||||||
|
Parse a video file for information including keyframes placement.
|
||||||
|
|
||||||
|
:param file: path to file
|
||||||
|
:type file: Path
|
||||||
|
:param mode: informs the function what to do
|
||||||
|
:type mode: str
|
||||||
|
|
||||||
|
:return: list of frame numbers, high resolution switch, frame length and resolution
|
||||||
|
:rtype: tuple[list[int], bool, int, int, int]
|
||||||
|
"""
|
||||||
|
if mode == "src":
|
||||||
|
kf_file = tmp_dir / "info_src.txt"
|
||||||
|
else:
|
||||||
|
kf_file = tmp_dir / "info.txt"
|
||||||
|
|
||||||
|
if kf_file.exists() and mode == "src" and (stage != 0 or resume):
|
||||||
|
with open(kf_file, "r") as f:
|
||||||
|
print("Loading cached scene information...")
|
||||||
|
lines = f.readlines()
|
||||||
|
return [int(line.strip()) for line in lines[1:-3]], lines[0].strip() == "True", int(lines[-3].strip()), int(lines[-2].strip()), int(lines[-1].strip())
|
||||||
|
try:
|
||||||
|
if mode == "src":
|
||||||
|
src = core.ffms2.Source(source=file, cachefile=f"{cache_file}")
|
||||||
|
else:
|
||||||
|
src = core.ffms2.Source(source=file, cache=False)
|
||||||
|
except:
|
||||||
|
print("Cannot retrieve file information. Did you run the previous stages?")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
nframe = len(src)
|
||||||
|
if mode == "len":
|
||||||
|
return 0, 0, nframe, 0, 0
|
||||||
|
|
||||||
|
fwidth, fheight = src[0].width, src[0].height
|
||||||
|
hr = True if fwidth * fheight > 1920 * 1080 else False
|
||||||
|
with open(kf_file, "w") as f:
|
||||||
|
f.write(str(hr)+"\n")
|
||||||
|
|
||||||
|
iframe_list = []
|
||||||
|
|
||||||
|
def get_props(n: int, f: vs.VideoFrame) -> None:
|
||||||
|
if f.props.get('_PictType') == 'I':
|
||||||
|
iframe_list.append(n)
|
||||||
|
|
||||||
|
clip_async_render(
|
||||||
|
src,
|
||||||
|
outfile=None,
|
||||||
|
progress=f'Finding scenes...',
|
||||||
|
callback=get_props
|
||||||
|
)
|
||||||
|
|
||||||
|
with open(kf_file, "a") as f:
|
||||||
|
f.write("\n".join(map(str, iframe_list)))
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print("I-Frames:", iframe_list)
|
||||||
|
print("Total I-Frames:", len(iframe_list))
|
||||||
|
|
||||||
|
with open(kf_file, "a") as f:
|
||||||
|
f.write(f"\n{nframe}\n{fwidth}\n{fheight}")
|
||||||
|
|
||||||
|
return iframe_list, hr, nframe, fwidth, fheight
|
||||||
|
|
||||||
|
def set_resuming_params(enc_file: Path, zones_file: Path, state: str) -> tuple[str, str, Path, int, int]:
|
||||||
|
"""
|
||||||
|
Determines where to resume encoding by trimming the current encode at the last full GOP,
|
||||||
|
summing previous trimmed chunks, creating offset zones file, and returning the skip/start options.
|
||||||
|
|
||||||
|
:param enc_file: path to fast pass encode
|
||||||
|
:type enc_file: Path
|
||||||
|
:param zones_file: path to original zones file
|
||||||
|
:type zones_file: Path
|
||||||
|
:param state:
|
||||||
|
:type state: str
|
||||||
|
|
||||||
|
:return: skip options, start options, offset zones file path and resolution
|
||||||
|
:rtype: tuple[str, str, Path, int, int]
|
||||||
|
"""
|
||||||
|
if not enc_file.exists():
|
||||||
|
return "", "", zones_file, "", ""
|
||||||
|
|
||||||
|
_, _, nframe_enc, _, _ = get_file_info(enc_file, "len")
|
||||||
|
_, _, nframe_src, _, _ = get_file_info(src_file, "src")
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print(f"Source: {nframe_src} frames\nEncode: {nframe_enc} frames")
|
||||||
|
|
||||||
|
if nframe_src == nframe_enc:
|
||||||
|
print(f"Nothing to resume in the {state} pass. Continuing...")
|
||||||
|
if state == "final":
|
||||||
|
print(f'Stage 4 complete!')
|
||||||
|
print(f'\nAuto-boost complete!')
|
||||||
|
exit(0)
|
||||||
|
return "", "", zones_file, "", ""
|
||||||
|
|
||||||
|
total_prev = get_total_previous_frames(enc_file)
|
||||||
|
|
||||||
|
ranges, _, _, fwidth, fheight = get_file_info(enc_file, "")
|
||||||
|
last_gop_start = ranges[-1]
|
||||||
|
|
||||||
|
resume_file = get_next_filename(enc_file)
|
||||||
|
trim_ivf_from_last_keyframe(enc_file, resume_file, last_gop_start)
|
||||||
|
|
||||||
|
total_resume_point = total_prev + last_gop_start
|
||||||
|
print(f"Resuming the {state} pass from frame {total_resume_point}...")
|
||||||
|
|
||||||
|
offset_zones_path = zones_file
|
||||||
|
if state == "final" and zones_file.exists():
|
||||||
|
offset_zones_path = get_next_filename(zones_file)
|
||||||
|
create_offset_zones_file(zones_file, offset_zones_path, total_resume_point)
|
||||||
|
|
||||||
|
return f"--skip {total_resume_point}", f"--start {total_resume_point}", offset_zones_path, fwidth, fheight
|
||||||
|
|
||||||
|
def fast_pass() -> None:
|
||||||
|
"""
|
||||||
|
Quick fast pass to gather scene complexity information.
|
||||||
|
"""
|
||||||
|
encoder_params = f' --speed {fast_speed} --quality {quality} --fast-decode 2 '
|
||||||
|
# --color-primaries bt709 --transfer-characteristics bt709 --matrix-coefficients bt709
|
||||||
|
if fast_params:
|
||||||
|
encoder_params = f'{fast_params} ' + encoder_params
|
||||||
|
|
||||||
|
encoder_params_list = encoder_params.split()
|
||||||
|
|
||||||
|
svt_resume_list = ""
|
||||||
|
vspipe_resume_list = ""
|
||||||
|
if resume:
|
||||||
|
svt_resume_string, vspipe_resume_string, _, fwidth, fheight = set_resuming_params(fast_output_file, "", "fast")
|
||||||
|
svt_resume_list = svt_resume_string.split()
|
||||||
|
vspipe_resume_list = vspipe_resume_string.split()
|
||||||
|
|
||||||
|
if file_ext in [".y4m", ".yuv"]:
|
||||||
|
|
||||||
|
fast_pass_command_y4m = [
|
||||||
|
'SvtAv1EncApp',
|
||||||
|
'-i', src_file,
|
||||||
|
*svt_resume_list,
|
||||||
|
'--progress', '1',
|
||||||
|
*encoder_params_list,
|
||||||
|
'-b', fast_output_file
|
||||||
|
]
|
||||||
|
|
||||||
|
try:
|
||||||
|
subprocess.run(fast_pass_command_y4m, text=True, check=True)
|
||||||
|
|
||||||
|
except subprocess.CalledProcessError as e:
|
||||||
|
print(f"The fast pass encountered an error:\n{e}\nDid you make sure the source is 10-bit?")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
else:
|
||||||
|
|
||||||
|
try:
|
||||||
|
fast_pass_command_vspipe = subprocess.Popen(
|
||||||
|
[
|
||||||
|
'vspipe', vpy_file,
|
||||||
|
*vspipe_resume_list,
|
||||||
|
'-c', 'y4m',
|
||||||
|
'-'
|
||||||
|
], stdout=subprocess.PIPE
|
||||||
|
)
|
||||||
|
|
||||||
|
fast_pass_command_svt = subprocess.Popen(
|
||||||
|
[
|
||||||
|
'SvtAv1EncApp',
|
||||||
|
'-i', '-',
|
||||||
|
'--progress', '1',
|
||||||
|
*encoder_params_list,
|
||||||
|
'-b', fast_output_file
|
||||||
|
], stdin=fast_pass_command_vspipe.stdout,
|
||||||
|
)
|
||||||
|
|
||||||
|
fast_pass_command_vspipe.stdout.close()
|
||||||
|
|
||||||
|
fast_pass_command_vspipe.wait()
|
||||||
|
fast_pass_command_svt.wait()
|
||||||
|
|
||||||
|
except subprocess.CalledProcessError as e:
|
||||||
|
print(f"The fast pass encountered an error:\n{e}")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
resume_file = tmp_dir / f"{fast_output_file.stem}__1.ivf"
|
||||||
|
if resume and resume_file.exists():
|
||||||
|
merge_ivf_parts(resume_file, fast_output_file, fwidth, fheight)
|
||||||
|
|
||||||
|
def final_pass() -> None:
|
||||||
|
"""
|
||||||
|
Final encoding pass with proper zone offsetting for resume functionality.
|
||||||
|
"""
|
||||||
|
encoder_params = f' --speed {final_speed} --quality {quality} '
|
||||||
|
if final_params:
|
||||||
|
encoder_params = f'{final_params} ' + encoder_params
|
||||||
|
|
||||||
|
encoder_params_list = encoder_params.split()
|
||||||
|
|
||||||
|
svt_resume_list = ""
|
||||||
|
vspipe_resume_list = ""
|
||||||
|
active_zones_path = zones_file
|
||||||
|
if resume:
|
||||||
|
svt_resume_string, vspipe_resume_string, active_zones_path, fwidth, fheight = set_resuming_params(tmp_final_output_file, zones_file, "final")
|
||||||
|
svt_resume_list = svt_resume_string.split()
|
||||||
|
vspipe_resume_list = vspipe_resume_string.split()
|
||||||
|
|
||||||
|
if file_ext in [".y4m", ".yuv"]:
|
||||||
|
|
||||||
|
final_pass_command_y4m = [
|
||||||
|
'SvtAv1EncApp',
|
||||||
|
'-i', src_file,
|
||||||
|
*svt_resume_list,
|
||||||
|
'--progress', '2',
|
||||||
|
*encoder_params_list
|
||||||
|
]
|
||||||
|
|
||||||
|
if not no_boosting:
|
||||||
|
final_pass_command_y4m.extend(['--config', str(active_zones_path)])
|
||||||
|
|
||||||
|
final_pass_command_y4m.extend(['-b', tmp_final_output_file])
|
||||||
|
|
||||||
|
try:
|
||||||
|
subprocess.run(final_pass_command_y4m, text=True, check=True)
|
||||||
|
|
||||||
|
except subprocess.CalledProcessError as e:
|
||||||
|
print(f"The final pass encountered an error:\n{e}\nDid you make sure the source is 10-bit?")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
else:
|
||||||
|
|
||||||
|
try:
|
||||||
|
final_pass_command_vspipe = subprocess.Popen(
|
||||||
|
[
|
||||||
|
'vspipe', vpy_file,
|
||||||
|
*vspipe_resume_list,
|
||||||
|
'-c', 'y4m',
|
||||||
|
'-'
|
||||||
|
], stdout=subprocess.PIPE
|
||||||
|
)
|
||||||
|
|
||||||
|
final_pass_command_svt = [
|
||||||
|
'SvtAv1EncApp',
|
||||||
|
'-i', '-',
|
||||||
|
'--progress', '2',
|
||||||
|
*encoder_params_list,
|
||||||
|
]
|
||||||
|
|
||||||
|
if not no_boosting:
|
||||||
|
final_pass_command_svt.extend(['--config', str(active_zones_path)])
|
||||||
|
|
||||||
|
final_pass_command_svt.extend(['-b', tmp_final_output_file])
|
||||||
|
|
||||||
|
final_pass_svt_process = subprocess.Popen(
|
||||||
|
final_pass_command_svt,
|
||||||
|
stdin=final_pass_command_vspipe.stdout
|
||||||
|
)
|
||||||
|
|
||||||
|
final_pass_command_vspipe.stdout.close()
|
||||||
|
|
||||||
|
final_pass_command_vspipe.wait()
|
||||||
|
final_pass_svt_process.wait()
|
||||||
|
|
||||||
|
except subprocess.CalledProcessError as e:
|
||||||
|
print(f"The final pass encountered an error:\n{e}")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
resume_file = tmp_dir / f"{tmp_final_output_file.stem}__1.ivf"
|
||||||
|
if resume and resume_file.exists():
|
||||||
|
merge_ivf_parts(resume_file, tmp_final_output_file, fwidth, fheight)
|
||||||
|
|
||||||
|
def calculate_ssimu2() -> None:
|
||||||
|
"""
|
||||||
|
Calculate SSIMULACRA2 metrics score.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
source_clip = core.ffms2.Source(source=src_file, cachefile=f"{cache_file}")
|
||||||
|
except:
|
||||||
|
print("Error indexing source file. Is it corrupted?")
|
||||||
|
exit(1)
|
||||||
|
try:
|
||||||
|
encoded_clip = core.ffms2.Source(source=fast_output_file, cache=False)
|
||||||
|
except:
|
||||||
|
print("Error indexing fast pass file. Did you run stage 1?")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
#source_clip = source_clip.resize.Bicubic(format=vs.RGBS, matrix_in_s='709').fmtc.transfer(transs="srgb", transd="linear", bits=32)
|
||||||
|
#encoded_clip = encoded_clip.resize.Bicubic(format=vs.RGBS, matrix_in_s='709').fmtc.transfer(transs="srgb", transd="linear", bits=32)
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print(f"Source: {len(source_clip)} frames\nEncode: {len(encoded_clip)} frames")
|
||||||
|
|
||||||
|
print("Calculating SSIMULACRA 2 scores...")
|
||||||
|
|
||||||
|
if cpu:
|
||||||
|
result = core.vszip.Metrics(source_clip, encoded_clip, mode=0)
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
result = core.vship.SSIMULACRA2(source_clip, encoded_clip)
|
||||||
|
except:
|
||||||
|
print("Vship not found or available, defaulting to vs-zip.")
|
||||||
|
try:
|
||||||
|
result = core.vszip.Metrics(source_clip, encoded_clip, mode=0)
|
||||||
|
except:
|
||||||
|
print("vs-zip not found either. Check your installation.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
for index, frame in enumerate(result.frames()):
|
||||||
|
score = frame.props['_SSIMULACRA2']
|
||||||
|
with ssimu2_log_file.open("w" if index == 0 else "a") as file:
|
||||||
|
file.write(f"{index}: {score}\n")
|
||||||
|
|
||||||
|
def metrics_aggregation(score_list: list[float]) -> tuple[float, float]:
|
||||||
|
"""
|
||||||
|
Takes a list of metrics scores and aggregatates them into the desired formats.
|
||||||
|
|
||||||
|
:param score_list: list of SSIMULACRA2 scores
|
||||||
|
:type score_list: list[float]
|
||||||
|
|
||||||
|
:return: average and 15th percentile scores
|
||||||
|
:rtype: tuple[float, float]
|
||||||
|
"""
|
||||||
|
filtered_score_list = [score if score >= 0 else 0.0 for score in score_list]
|
||||||
|
sorted_score_list = sorted(filtered_score_list)
|
||||||
|
average = sum(filtered_score_list)/len(filtered_score_list)
|
||||||
|
percentile_15 = quantiles(sorted_score_list, n=100)[14]
|
||||||
|
min_score = sorted_score_list[0]
|
||||||
|
return (average, percentile_15, min_score)
|
||||||
|
|
||||||
|
def calculate_zones(ranges: list[float], hr: bool, nframe: int) -> None:
|
||||||
|
"""
|
||||||
|
Retrieves SSIMULACRA2 scores, runs metrics aggregation and make CRF adjustement decisions.
|
||||||
|
|
||||||
|
:param ranges: scene changes list
|
||||||
|
:type ranges: list
|
||||||
|
:param hr: switch for high resolution sources
|
||||||
|
:type hr: bool
|
||||||
|
:param nframe: source frame amount
|
||||||
|
:type nframe: int
|
||||||
|
|
||||||
|
:return: string containing zones information
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
ssimu2_scores: list[int] = []
|
||||||
|
|
||||||
|
if not ssimu2_log_file.exists():
|
||||||
|
print("Cannot find the metrics file. Did you run the previous stages?")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
with ssimu2_log_file.open("r") as file:
|
||||||
|
for line in file:
|
||||||
|
match = re.search(r"([0-9]+): ([0-9]+\.[0-9]+)", line)
|
||||||
|
if match:
|
||||||
|
score = float(match.group(2))
|
||||||
|
ssimu2_scores.append(score)
|
||||||
|
else:
|
||||||
|
if verbose:
|
||||||
|
print(line)
|
||||||
|
|
||||||
|
ssimu2_total_scores = []
|
||||||
|
ssimu2_percentile_15_total = []
|
||||||
|
ssimu2_min_total = []
|
||||||
|
|
||||||
|
for index in range(len(ranges)):
|
||||||
|
ssimu2_chunk_scores = []
|
||||||
|
if index == len(ranges)-1:
|
||||||
|
ssimu2_frames = nframe - ranges[index]
|
||||||
|
else:
|
||||||
|
ssimu2_frames = ranges[index+1] - ranges[index]
|
||||||
|
for scene_index in range(ssimu2_frames):
|
||||||
|
ssimu2_score = ssimu2_scores[ranges[index]+scene_index]
|
||||||
|
ssimu2_chunk_scores.append(ssimu2_score)
|
||||||
|
ssimu2_total_scores.append(ssimu2_score)
|
||||||
|
(ssimu2_average, ssimu2_percentile_15, ssimu2_min) = metrics_aggregation(ssimu2_chunk_scores)
|
||||||
|
ssimu2_percentile_15_total.append(ssimu2_percentile_15)
|
||||||
|
ssimu2_min_total.append(ssimu2_min)
|
||||||
|
(ssimu2_average, ssimu2_percentile_15, ssimu2_min) = metrics_aggregation(ssimu2_total_scores)
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
index_min = min(range(len(ssimu2_scores)), key=ssimu2_scores.__getitem__)
|
||||||
|
print(f'SSIMULACRA2:')
|
||||||
|
print(f'Mean score: {ssimu2_average:.4f}')
|
||||||
|
print(f'15th percentile: {ssimu2_percentile_15:.4f}')
|
||||||
|
print(f'Worst scoring frame: {index_min} ({ssimu2_scores[index_min]:.4f})')
|
||||||
|
|
||||||
|
match quality:
|
||||||
|
case "low":
|
||||||
|
crf = 40 if hr else 35
|
||||||
|
case "medium":
|
||||||
|
crf = 35 if hr else 30
|
||||||
|
case "high":
|
||||||
|
crf = 30 if hr else 25
|
||||||
|
|
||||||
|
for index in range(len(ranges)):
|
||||||
|
|
||||||
|
# Calculate CRF adjustment using aggressive or normal multiplier
|
||||||
|
multiplier = 40 if aggressive else 20
|
||||||
|
adjustment = ceil((1.0 - (ssimu2_percentile_15_total[index] / ssimu2_average)) * multiplier)
|
||||||
|
new_crf = crf - adjustment
|
||||||
|
|
||||||
|
# Apply sane limits
|
||||||
|
limit = 10 if unshackle else 5
|
||||||
|
if adjustment < - limit: # Positive deviation (increasing CRF)
|
||||||
|
new_crf = crf + limit
|
||||||
|
elif adjustment > limit: # Negative deviation (decreasing CRF)
|
||||||
|
new_crf = crf - limit
|
||||||
|
|
||||||
|
if index == len(ranges)-1:
|
||||||
|
end_range = nframe
|
||||||
|
else:
|
||||||
|
end_range = ranges[index+1]
|
||||||
|
|
||||||
|
if verbose:
|
||||||
|
print(f'Chunk: [{ranges[index]}:{end_range}]\n'
|
||||||
|
f'15th percentile: {ssimu2_percentile_15_total[index]:.4f}\n'
|
||||||
|
f'CRF adjustment: {-adjustment}\n'
|
||||||
|
f'Final CRF: {new_crf}\n')
|
||||||
|
|
||||||
|
if index == 0:
|
||||||
|
with zones_file.open("w") as file:
|
||||||
|
file.write(f"Zones : {ranges[index]},{end_range-1},{new_crf};")
|
||||||
|
else:
|
||||||
|
with zones_file.open("a") as file:
|
||||||
|
file.write(f"{ranges[index]},{end_range-1},{new_crf};")
|
||||||
|
|
||||||
|
if no_boosting:
|
||||||
|
stage = 4
|
||||||
|
|
||||||
|
match stage:
|
||||||
|
case 0:
|
||||||
|
if stage_resume < 2:
|
||||||
|
fast_pass()
|
||||||
|
with open(stage_file, "w") as f:
|
||||||
|
f.write("2")
|
||||||
|
print(f'Stage 1 complete!')
|
||||||
|
if stage_resume < 3:
|
||||||
|
ranges, hr, nframe, _, _ = get_file_info(fast_output_file, "")
|
||||||
|
calculate_ssimu2()
|
||||||
|
with open(stage_file, "w") as f:
|
||||||
|
f.write("3")
|
||||||
|
print(f'Stage 2 complete!')
|
||||||
|
if stage_resume < 4:
|
||||||
|
calculate_zones(ranges, hr, nframe)
|
||||||
|
with open(stage_file, "w") as f:
|
||||||
|
f.write("4")
|
||||||
|
print(f'Stage 3 complete!')
|
||||||
|
if stage_resume < 5:
|
||||||
|
final_pass()
|
||||||
|
shutil.move(tmp_final_output_file, final_output_file)
|
||||||
|
with open(stage_file, "w") as f:
|
||||||
|
f.write("5")
|
||||||
|
print(f'Stage 4 complete!')
|
||||||
|
case 1:
|
||||||
|
fast_pass()
|
||||||
|
print(f'Stage 1 complete!')
|
||||||
|
case 2:
|
||||||
|
calculate_ssimu2()
|
||||||
|
print(f'Stage 2 complete!')
|
||||||
|
case 3:
|
||||||
|
ranges, hr, nframe, _, _ = get_file_info(fast_output_file, "")
|
||||||
|
calculate_zones(ranges, hr, nframe)
|
||||||
|
print(f'Stage 3 complete!')
|
||||||
|
case 4:
|
||||||
|
final_pass()
|
||||||
|
shutil.move(tmp_final_output_file, final_output_file)
|
||||||
|
if not no_boosting:
|
||||||
|
print(f'Stage 4 complete!')
|
||||||
|
case _:
|
||||||
|
print(f"Stage argument invalid, exiting.")
|
||||||
|
exit(1)
|
||||||
|
|
||||||
|
print(f"\nAuto-boost complete!")
|
||||||
27
Auto-Boost-Essential/README.md
Normal file
27
Auto-Boost-Essential/README.md
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
# Auto-Boost-Essential
|
||||||
|
|
||||||
|
Auto-Boost-Essential is the latest iteration of the Auto-Boost formula, streamlined and refined for greater convenience, speeds and boosting gains!
|
||||||
|
|
||||||
|
This encoding script is intended to be paired with my [SVT-AV1-Essential](https://github.com/nekotrix/SVT-AV1-Essential) encoder fork.
|
||||||
|
SVT-AV1-Essential sports *excellent* quality consistency, but Auto-Boost-Essential offers *exceptional* consistency!
|
||||||
|
|
||||||
|
**Here is how it works:** the script runs a first encoder fass-pass, finds scenes based on the introduced keyframes, calculate metrics scores, automatically adjusts the CRF of scenes in order to increase quality consistency and then runs a final-pass with these adjustements.
|
||||||
|
|
||||||
|
The quality metric at play this time again is SSIMULACRA2.
|
||||||
|
|
||||||
|
Auto-Boost-Essential can be considered a helper script, as all you need to do is provide an input video file and it will manage everything for you:
|
||||||
|
```bash
|
||||||
|
python Auto-Boost-Essential.py "my_video_file.mp4"
|
||||||
|
```
|
||||||
|
|
||||||
|
Results:
|
||||||
|
| Metrics | Speed |
|
||||||
|
|-----------------------------------------------|---------------------------------------------|
|
||||||
|
| 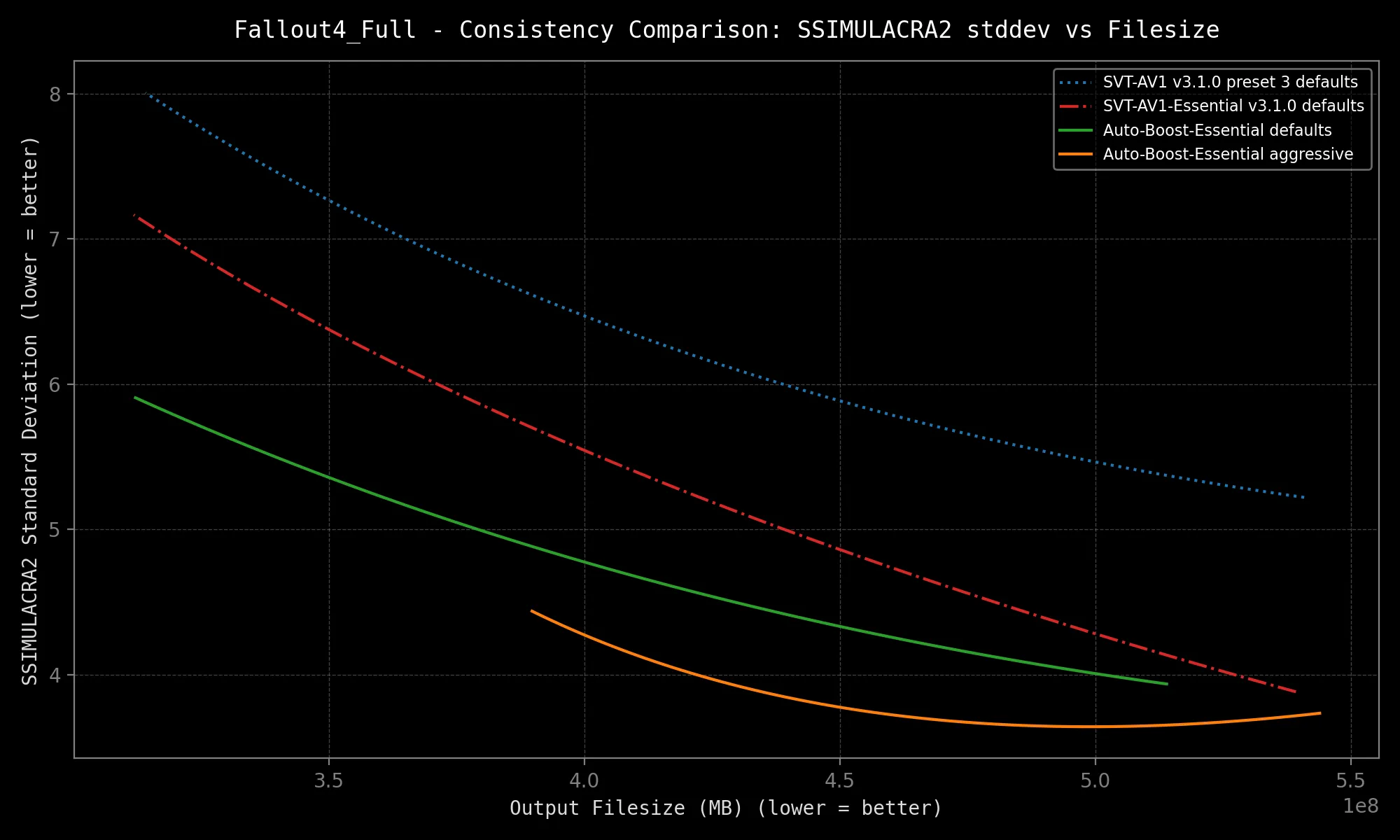 | 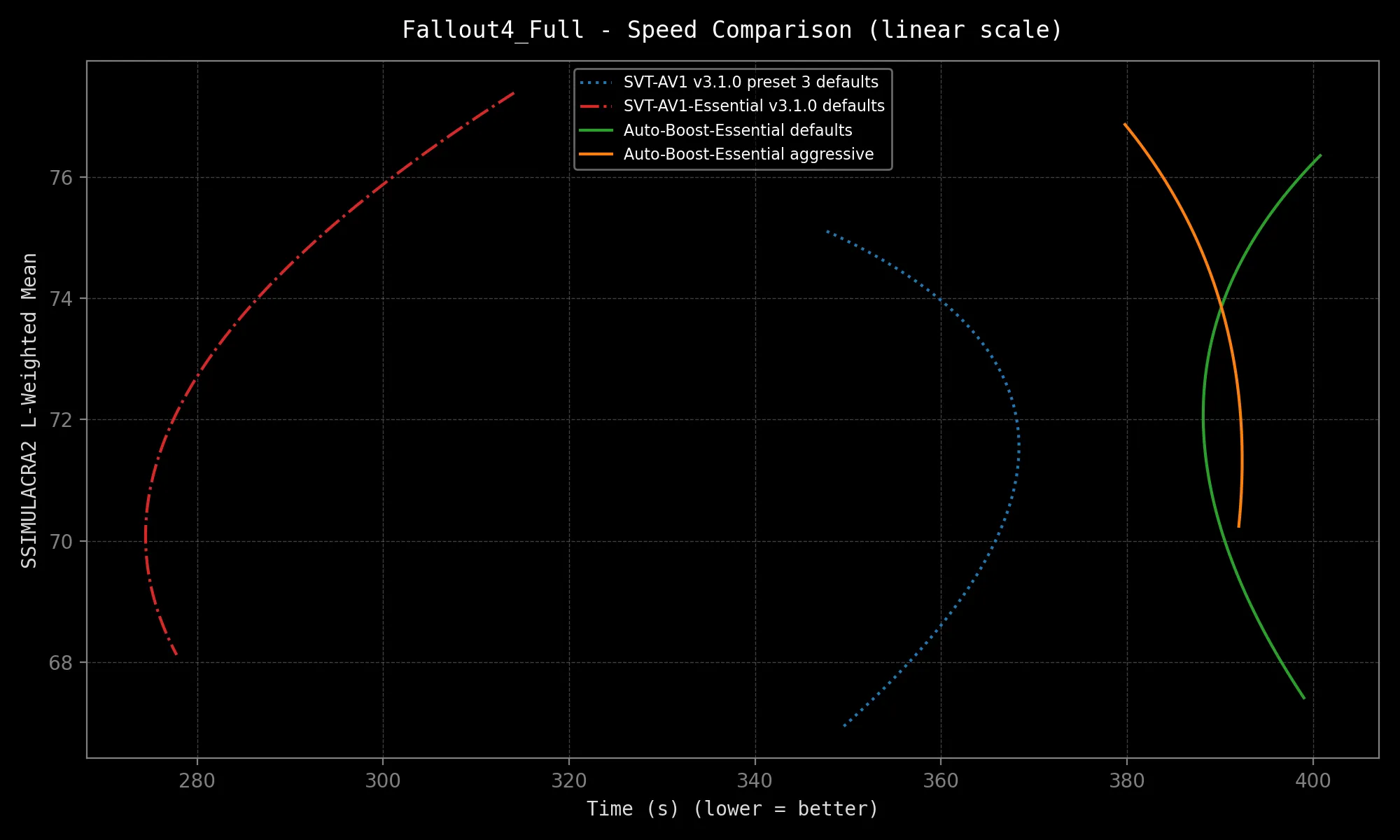 |
|
||||||
|
| 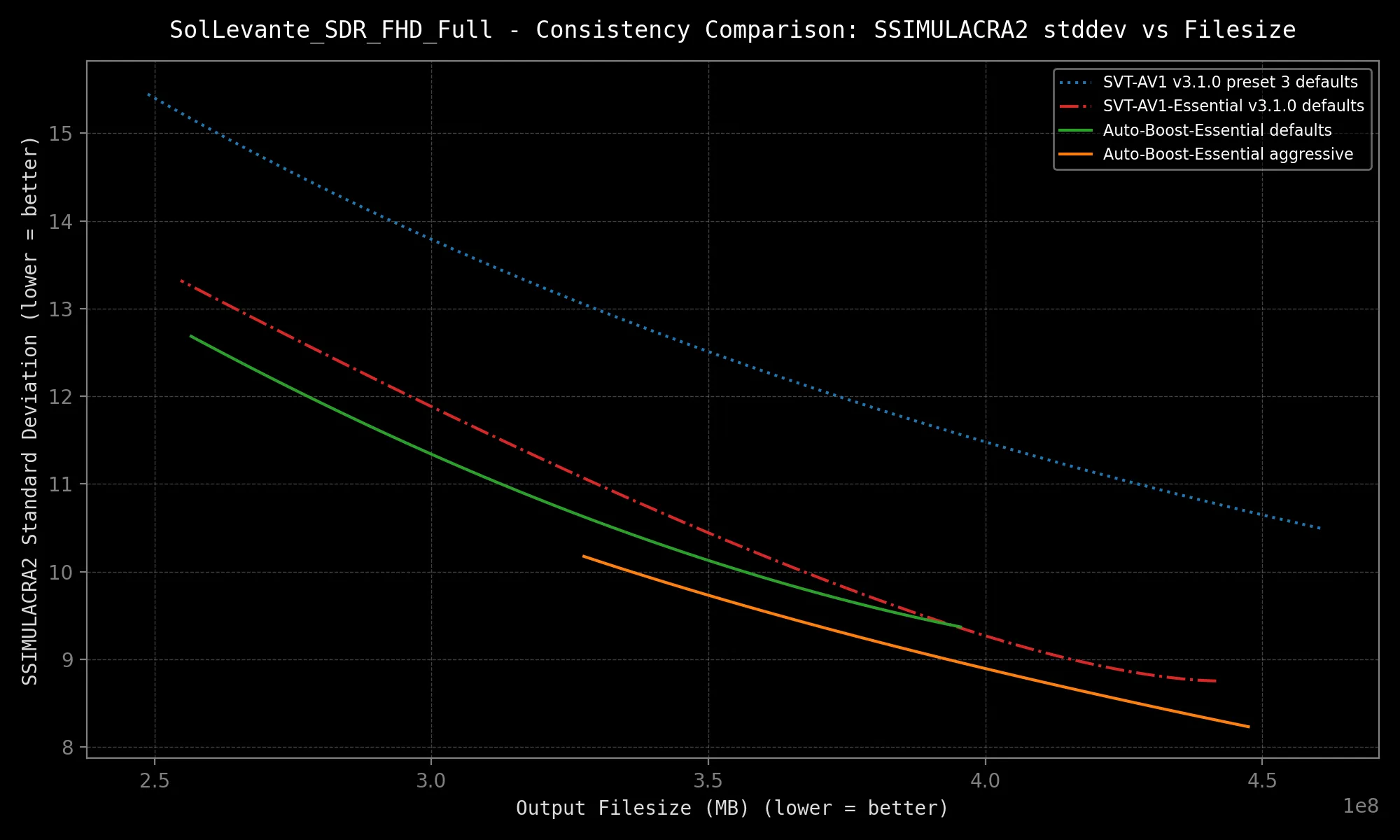 | 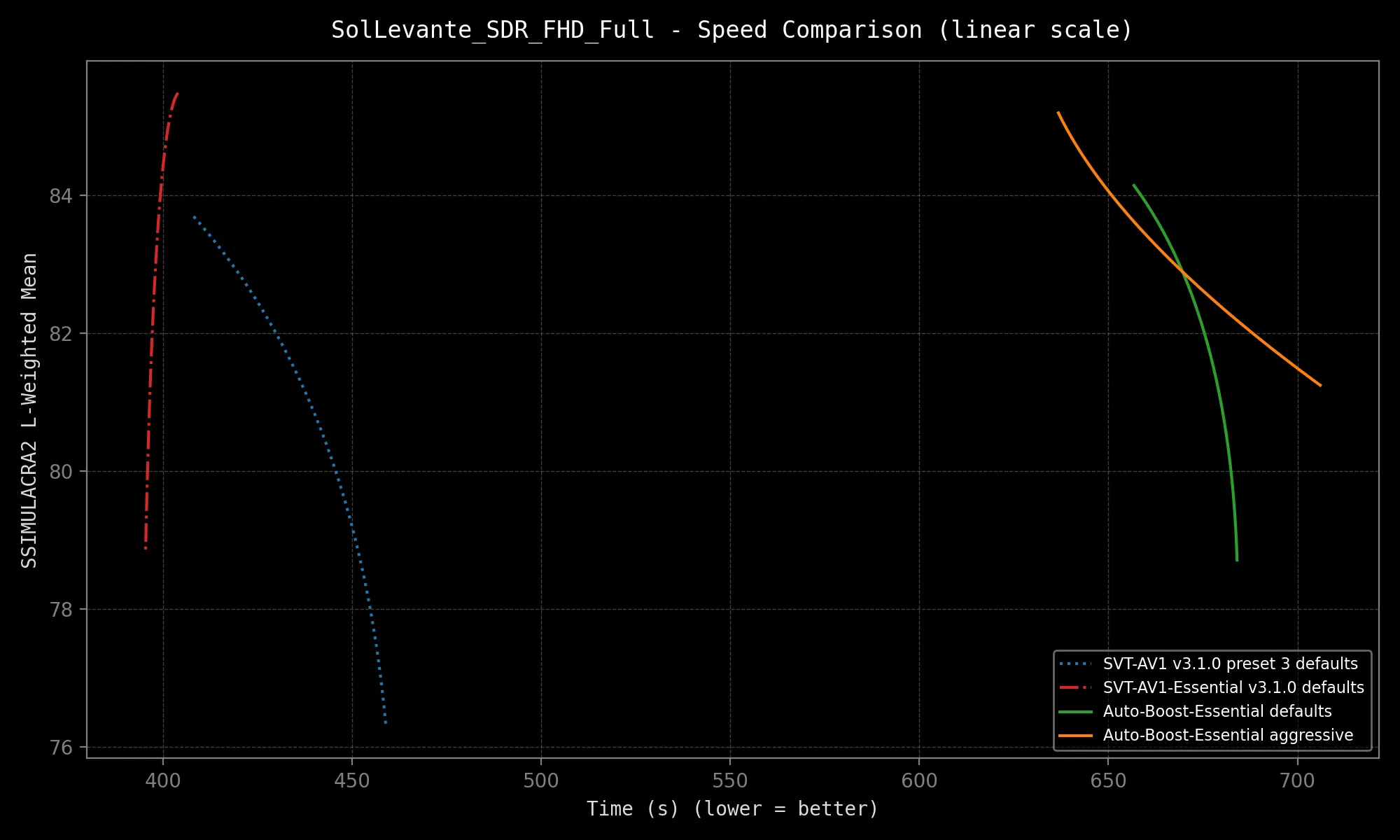 |
|
||||||
|
|
||||||
|
*Speed may vary depending on your hardware configuration and source resolution.*
|
||||||
|
|
||||||
|
The above results are not even best-case scenarios. The selected samples are very complex. More gains are expected on your average clip, granted it contains more than one scene at a minimum!
|
||||||
|
|
||||||
|
The script is also capable of resuming unfinished encodes, and can also be run with boosting disabled!
|
||||||
@@ -1 +0,0 @@
|
|||||||
# Auto-Boost-Next
|
|
||||||
@@ -1,8 +1,10 @@
|
|||||||
# Auto-boost Algorithm
|
# Auto-boost Algorithm
|
||||||
|
|
||||||
## Auto-Boost-Next:
|
## Auto-Boost-Essential:
|
||||||
|
|
||||||
_Soon:tm:_
|
Latest encoding script intended for use with [SVT-AV1-Essential](https://github.com/nekotrix/SVT-AV1-Essential) with a bunch of convenient features.
|
||||||
|
|
||||||
|
Details are given in the Auto-Boost-Essential folder [README](Auto-Boost-Essential).
|
||||||
|
|
||||||
## Version 2.5: SSIMULACRA2&XPSNR-based
|
## Version 2.5: SSIMULACRA2&XPSNR-based
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user